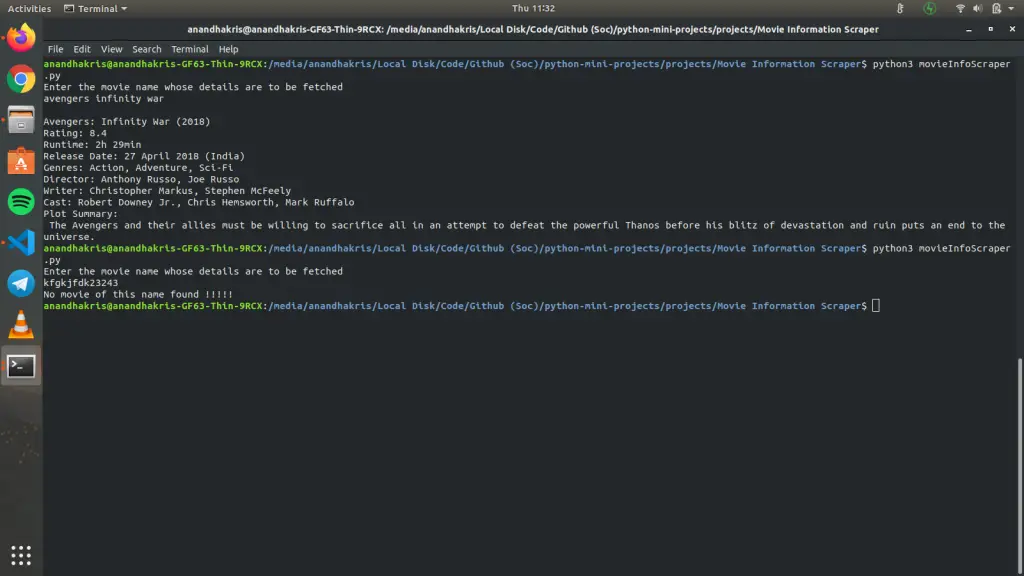
This script obtains movie details by scraping the IMDB website.
Prerequisites
- beautifulsoup4
- requests==2.23.0
- Run to install required external modules.
pip install -r requirements.txt Code language: CSS (css)Run the Script:
<code>python3 movieInfoScraper.py</code>Code language: HTML, XML (xml)Source Code:
movieInfoScraper.py
from bs4 import BeautifulSoup
import requests
# Function to get Movie Details
def getMovieDetails(movieName):
# Base URL of IMDB website
url = 'https://www.imdb.com'
# Query to find movie title
query = '/search/title?title='
# Empty dictionary to store movie Details
movieDetails = {}
# Query formed
movienamequery = query+'+'.join(movieName.strip().split(' '))
# WebPage is obtained and parsed
html = requests.get(url+movienamequery+'&title_type=feature')
bs = BeautifulSoup(html.text, 'html.parser')
# Gets the first movie that appears in title section
result = bs.find('h3', {'class': 'lister-item-header'})
if result is None:
return None
movielink = url+result.a.attrs['href']
movieDetails['name'] = result.a.text
# Gets the page with movie details
html = requests.get(movielink)
bs = BeautifulSoup(html.text, 'html.parser')
# Year
try:
movieDetails['year'] = bs.find('span', {'id': 'titleYear'}).a.text
except AttributeError:
movieDetails['year'] = 'Not available'
subtext = bs.find('div', {'class': 'subtext'})
# Rating,Genres,Runtime,Release Date,
movieDetails['genres'] = [
i.text for i in subtext.findAll('a', {'title': None})]
try:
movieDetails['rating'] = bs.find(
'div', {'class': 'ratingValue'}).span.text
movieDetails['runtime'] = subtext.time.text.strip()
except AttributeError:
movieDetails['rating'] = 'Not yet rated'
movieDetails['runtime'] = 'Not available'
movieDetails['release_date'] = subtext.find(
'a', {'title': 'See more release dates'}).text.strip()
# Gets the credit section of the page
creditSummary = bs.findAll('div', {'class': 'credit_summary_item'})
# Directors,Writers and Cast
movieDetails['directors'] = [i.text for i in creditSummary[0].findAll('a')]
movieDetails['writers'] = [i.text for i in creditSummary[1].findAll(
'a') if 'name' in i.attrs['href']]
try:
movieDetails['cast'] = [i.text for i in creditSummary[2].findAll(
'a') if 'name' in i.attrs['href']]
# For some films, writer details are not provided
except IndexError:
movieDetails['cast']=movieDetails['writers']
movieDetails['writers']='Not found'
# The plot is seperate AJAX call and does not come in the html page, So one more request to plotsummary page
html = requests.get(movielink+'plotsummary')
bs = BeautifulSoup(html.text, 'html.parser')
# Plot
movieDetails['plot'] = bs.find(
'li', {'class': 'ipl-zebra-list__item'}).p.text.strip()
# Returns the dictionary with movie details
return movieDetails
if __name__ == "__main__":
movieName = input('Enter the movie name whose details are to be fetched\n')
movieDetails = getMovieDetails(movieName)
if movieDetails is None:
print('No movie of this name found !!!!!')
quit()
print('\n{movie} ({year})'.format(
movie=movieDetails['name'], year=movieDetails['year']))
print('Rating:', movieDetails['rating'])
print('Runtime:', movieDetails['runtime'])
print('Release Date:', movieDetails['release_date'])
print('Genres:', ', '.join(movieDetails['genres']))
print('Director:', ', '.join(movieDetails['directors']))
print('Writer:', ', '.join(movieDetails['writers']))
print('Cast:', ', '.join(movieDetails['cast']))
print('Plot Summary:\n', movieDetails['plot'])Code language: PHP (php)Output: