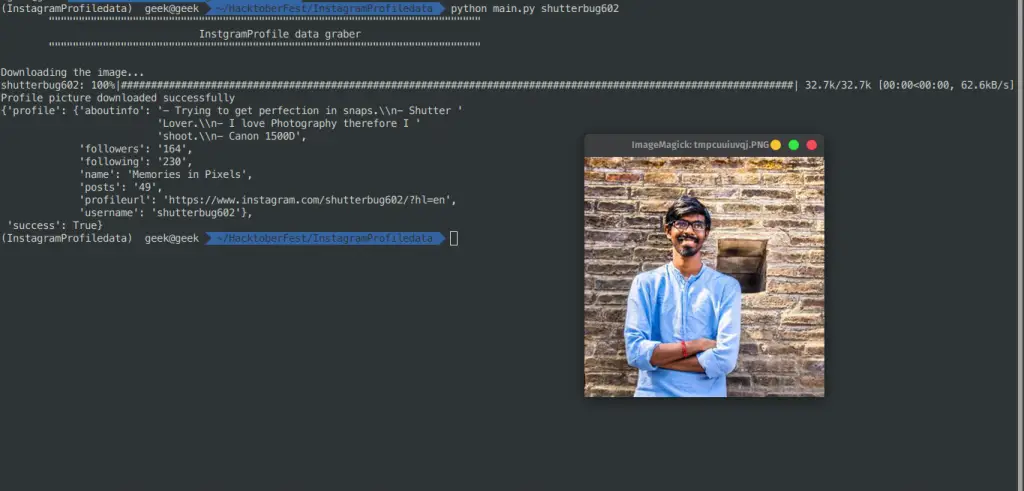
Instagram profile information.
Install Packages:
pip install -r requirements.txtCode language: CSS (css)Requirements:
- appdirs==1.4.3
- beautifulsoup4==4.9.2
- bs4==0.0.1
- CacheControl==0.12.6
- certifi==2019.11.28
- chardet==3.0.4
- colorama==0.4.3
- contextlib2==0.6.0
- distlib==0.3.0
- distro==1.4.0
- html5lib==1.0.1
- idna==2.8
- ipaddr==2.2.0
- lockfile==0.12.2
- lxml==4.6.3
- msgpack==0.6.2
- packaging==20.3
- pep517==0.8.2
- Pillow==8.3.2
- progress==1.5
- pyparsing==2.4.6
- pytoml==0.1.21
- requests==2.22.0
- retrying==1.3.3
- six==1.14.0
- soupsieve==2.0.1
- tqdm==4.50.0
- urllib3==1.26.5
- webencodings==0.5.1
Source Code:
profilepic.py
from tqdm import tqdm
import requests
import re
from PIL import Image
#Function to download profile picture of instagram accounts
def pp_download(username):
url = "https://www.instagram.com/{}/".format(username)
x = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com', url)
if x:
check_url1 = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com[/].*\?hl=[a-z-]{2,5}', url)
check_url2 = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com$|^(https:)[/][/]www.([^/]+[.])*instagram.com/$', url)
check_url3 = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com[/][a-zA-Z0-9_]{1,}$', url)
check_url4 = re.match(r'^(https:)[/][/]www.([^/]+[.])*instagram.com[/][a-zA-Z0-9_]{1,}[/]$', url)
if check_url3:
final_url = url + '/?__a=1'
if check_url4:
final_url = url + '?__a=1'
if check_url2:
final_url = print("Please enter an URL related to a profile")
exit()
if check_url1:
alpha = check_url1.group()
final_url = re.sub('\\?hl=[a-z-]{2,5}', '?__a=1', alpha)
try:
if check_url3 or check_url4 or check_url2 or check_url1:
req = requests.get(final_url)
get_status = requests.get(final_url).status_code
get_content = req.content.decode('utf-8')
if get_status == 200:
print("\nDownloading the image...")
find_pp = re.search(r'profile_pic_url_hd\":\"([^\'\" >]+)', get_content)
pp_link = find_pp.group()
pp_final = re.sub('profile_pic_url_hd":"', '', pp_link)
file_size_request = requests.get(pp_final, stream=True)
file_size = int(file_size_request.headers['Content-Length'])
block_size = 1024
t=tqdm(total=file_size, unit='B', unit_scale=True, desc=username, ascii=True)
with open(username + '.jpg', 'wb') as f:
for data in file_size_request.iter_content(block_size):
t.update(len(data))
f.write(data)
t.close()
#Show image
im = Image.open(username +".jpg")
im.show()
print("Profile picture downloaded successfully")
except Exception:
print('error')
Code language: PHP (php)main.py
import requests
from lxml import html
import re
import sys
import pprint
from profilepic import pp_download
def banner():
print('\t""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""')
print('\t InstgramProfile data graber ')
print('\t""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""')
def main(username):
banner()
'''main function accept instagram username
return an dictionary object containging profile deatils
'''
url = "https://www.instagram.com/{}/?hl=en".format(username)
page = requests.get(url)
tree = html.fromstring(page.content)
data = tree.xpath('//meta[starts-with(@name,"description")]/@content')
if data:
data = tree.xpath('//meta[starts-with(@name,"description")]/@content')
data = data[0].split(', ')
followers = data[0][:-9].strip()
following = data[1][:-9].strip()
posts = re.findall(r'\d+[,]*', data[2])[0]
name = re.findall(r'name":"([^"]+)"', page.text)[0]
aboutinfo = re.findall(r'"description":"([^"]+)"', page.text)[0]
instagram_profile = {
'success': True,
'profile': {
'name': name,
'profileurl': url,
'username': username,
'followers': followers,
'following': following,
'posts': posts,
'aboutinfo': aboutinfo
}
}
else:
instagram_profile = {
'success': False,
'profile': {}
}
return instagram_profile
# python main.py username
if __name__ == "__main__":
if len(sys.argv) == 2:
output = main(sys.argv[-1])
pp_download(sys.argv[-1])
pprint.pprint(output)
else:
print('Invalid paramaters Valid Command \n\tUsage : python main.py username')
Code language: PHP (php)InstgramProfile.py
import requests
from lxml import html
import re
import sys
def main(username):
'''main function accept instagram username
return an dictionary object containging profile deatils
'''
url = "https://www.instagram.com/{}/?hl=en".format(username)
page = requests.get(url)
tree = html.fromstring(page.content)
data = tree.xpath('//meta[starts-with(@name,"description")]/@content')
if data:
data = tree.xpath('//meta[starts-with(@name,"description")]/@content')
data = data[0].split(', ')
followers = data[0][:-9].strip()
following = data[1][:-9].strip()
posts = re.findall(r'\d+[,]*', data[2])[0]
name = re.findall(r'name":"\w*[\s]+\w*"', page.text)[-1][7:-1]
aboutinfo = re.findall(r'"description":"([^"]+)"', page.text)[0]
instagram_profile = {
'success': True,
'profile': {
'name': name,
'profileurl': url,
'username': username,
'followers': followers,
'following': following,
'posts': posts,
'aboutinfo': aboutinfo
}
}
else:
instagram_profile = {
'success': False,
'profile': {}
}
return instagram_profile
# python InstgramProfile.py username
if __name__ == "__main__":
'''driver code'''
if len(sys.argv) == 2:
output = main(sys.argv[-1])
print(output)
else:
print('=========>Invalid paramaters Valid Comma
Code language: PHP (php)Execute Program:
python InstgramProfile.py <username>Code language: HTML, XML (xml)Output: