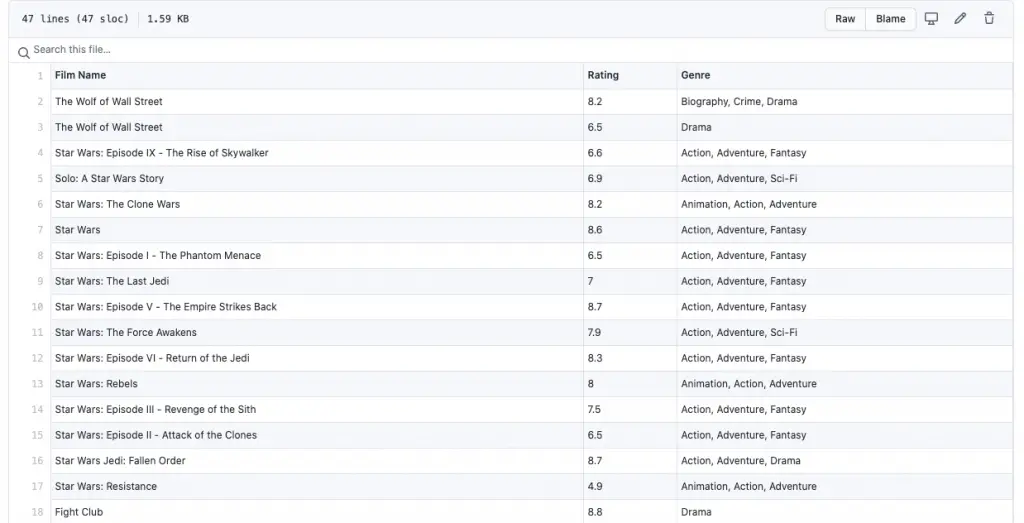
- This script is used to fetch the Ratings and Genre of the films in your films folder that match with ones on IMDb, the data is scraped from IMDB’s official website and store in a csv file.
- The csv file can be used for analysis then, sorting acc to rating etc.
Input:
- Path of the directory which contains the films.
Output:
- A new csv file is made – ‘film_ratings.csv’ which contains the ratings for the films in your directory.
Requirement:
- beautifulsoup4==4.9.1
- certifi==2020.6.20
- chardet==3.0.4
- idna==2.10
- pandas==1.1.2
- python-dateutil==2.8.1
- pytz==2020.1
- requests==2.24.0
- six==1.15.0
- soupsieve==2.0.1
- urllib3==1.26.5
Prerequisites:
- This program uses and external dependency of ‘BeautifulSoup’ (for web scraping), ‘requests’ (for fetching content of the webpage), ‘pandas’ (to make the csv file), ‘os’ (to get data from directory).
- These libraries can be installed easily by using the following command: pip install -r requirements.txt
Run the Script:
- Install the requirements.
- Inside the find_IMDb_rating.py, update the directory path.
- Type the following command: python find_IMDb_rating.py
- A csv file with rating will be created in the same directory as the python file.
Source Code:
find_IMDb_rating.py
from bs4 import BeautifulSoup
import requests
import pandas as pd
import os
# Setting up session
s = requests.session()
# List contaiting all the films for which data has to be scraped from IMDB
films = []
# Lists contaiting web scraped data
names = []
ratings = []
genres = []
# Define path where your films are present
# For eg: "/Users/utkarsh/Desktop/films"
path = input("Enter the path where your films are: ")
# Films with extensions
filmswe = os.listdir(path)
for film in filmswe:
# Append into my films list (without extensions)
films.append(os.path.splitext(film)[0])
# print(os.path.splitext(film)[0])
for line in films:
# x = line.split(", ")
title = line.lower()
# release = x[1]
query = "+".join(title.split())
URL = "https://www.imdb.com/search/title/?title=" + query
print(URL)
# print(release)
try:
response = s.get(URL)
#getting contect from IMDB Website
content = response.content
# print(response.status_code)
soup = BeautifulSoup(response.content, features="html.parser")
#searching all films containers found
containers = soup.find_all("div", class_="lister-item-content")
for result in containers:
name1 = result.h3.a.text
name = result.h3.a.text.lower()
# Uncomment below lines if you want year specific as well, define year variable before this
# year = result.h3.find(
# "span", class_="lister-item-year text-muted unbold"
# ).text.lower()
#if film found (searching using name)
if title in name:
#scraping rating
rating = result.find("div",class_="inline-block ratings-imdb-rating")["data-value"]
#scraping genre
genre = result.p.find("span", class_="genre")
genre = genre.contents[0]
#appending name, rating and genre to individual lists
names.append(name1)
ratings.append(rating)
genres.append(genre)
except Exception:
print("Try again with valid combination of tile and release year")
#storing in pandas dataframe
df = pd.DataFrame({'Film Name':names,'Rating':ratings,'Genre':genres})
#making csv using pandas
df.to_csv('film_ratings.csv', index=False, encoding='utf-8')
Output: